รู้จัก Stable Diffusion เบื้องต้น ฉบับยังไม่ลองทำ
พอดี Bittoon DAO Learning มี session “สอนการสร้างภาพด้วย AI โดยใช้ Stable Diffusion” สอนโดยคุณ Max เป็น Admin กลุ่ม Stable Diffusion Thailand และ เจ้าของเพจ BearHead ก็เลยมาสรุปว่าเอ้อมันคืออะไร แล้วมันต่างจาก Midjourney ยังไง แล้วต้องทำยังไงบ้าง

ก่อนเริ่ม session นี้ มีการฝากกลุ่ม Stable Diffusion Thailand บน Facebook พอเข้าไปดูผลงานในนั้นคืออย่างเทพมาก โอ้มาโอ้มาก้อด (ใส่เสียงนิวจีนส์)

คลิปย้อนหลังจ้า
Stable Diffusion คืออะไร?
คือ tool ที่ AI generate ภาพมาให้ แบบ text-to-image มี latent diffusion model ที่สามารถสร้างภาพจาก text prompt ได้

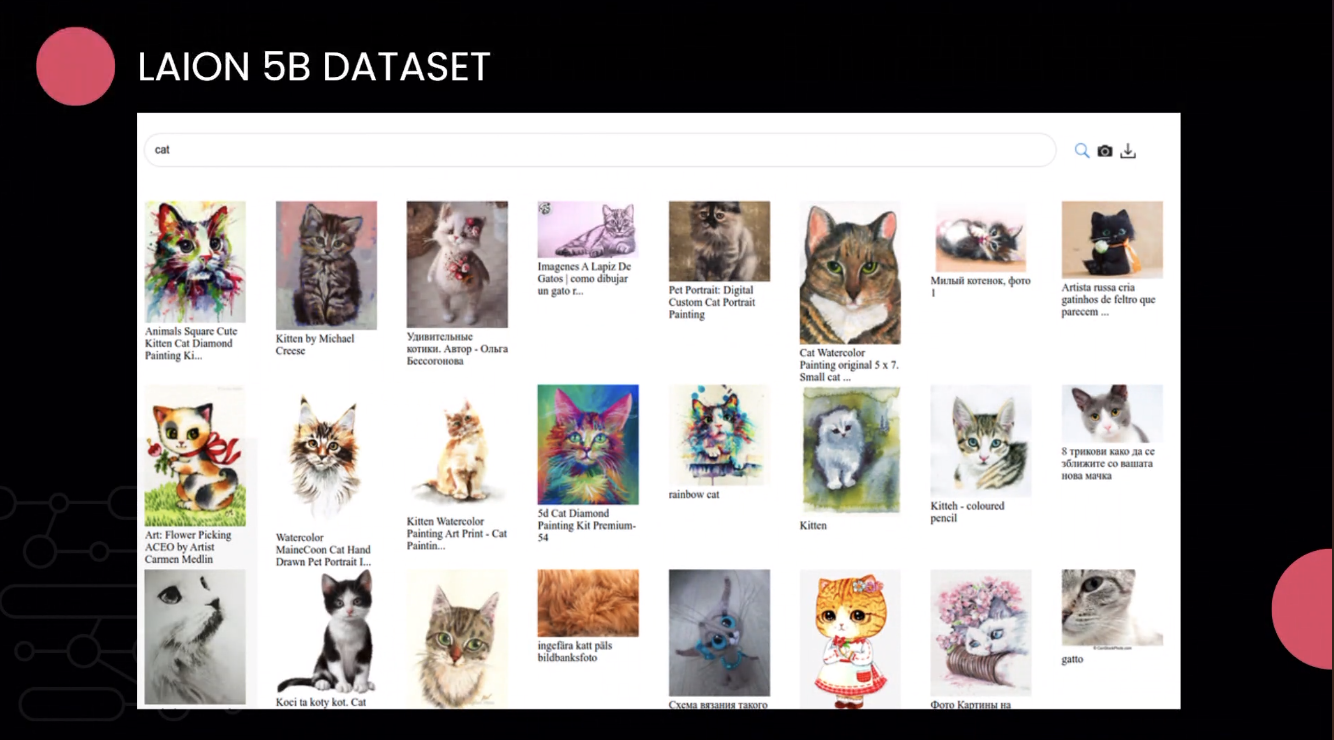
Stable Diffusion ถูกพัฒนาโดยบริษัท Stability.ai โดยนำฐานข้อมูลจาก LAION มาสร้างเป็น text-to-image model โดย learning จากภาพทั้งหมด 5 พันล้านภาพบน internet ทำให้ตัว dataset ของเขารู้จักแทบรู้จักทุกอย่าง จาก prompt จะดึงของใน model รูปใน internet
ความแตกต่างของ Stable Diffusion กับโปรแกรม generative AI อื่น ๆ คือ สามารถใส่กระดูกได้ สามารถกำหนดท่าต่าง ๆ ได้ เช่น ชูสองนิ้ว และเป็น open source ซึ่งเหมาะกับการพัฒนามากกว่า
กระบวนการสร้างภาพของ Stable Diffusion
เกิดจาก
- Denoise
- Prompt ชุดคำสั่ง keyword ในการสร้าง
Denoise
เป็นการสร้าง pixel มาใหม่ โดยการสร้าง model ให้ AI เรียนรู้ภาพนี้ ใส่ noise นิดนึง ให้ AI วาดออกมา และให้ถอดกลับมาเป็นภาพเดิม
step มันจะเริ่มมาจาก noise ที่ไม่มีอะไรเลย มา denoise จนกลายเป็นภาพ ซึ่ง noise อันนี้มัน random ขึ้นมาเฉย ๆ แล้ววาดขึ้นมา (ใน Stable Diffusion noise ที่ว่าเป็น seed)
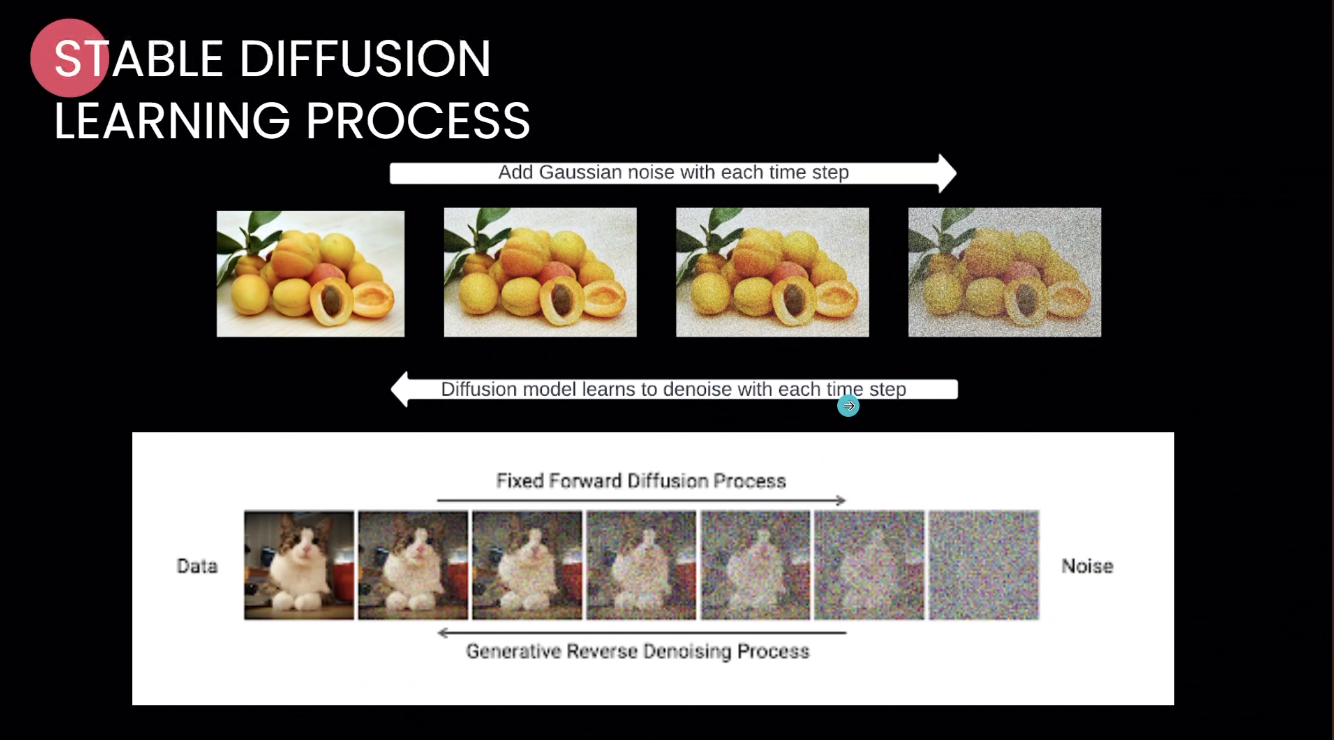



เมื่อสร้างภาพจาก noise ได้ ก็สามารถวาดภาพจากไม่มีอะไรเลยได้ คือ สามารถสร้างภาพที่ไม่มีใน dataset มาวาดพร้อมกัน
เช่น รูปเด็กสาวในชามราเมง AI จะวาดเด็กสาว และชามราเมง พร้อมกัน
ส่วนรูปมือ มี model ให้ train น้อย จึงมีความหลากหลายน้อย ไม่รู้ว่าอันไหนถูกต้อง ข้อดีคือ สร้างภาพได้เร็ว ได้ใน 20 วินาที แต่ข้อเสียคือควบคุมอะไรพวกนี้ไม่ได้

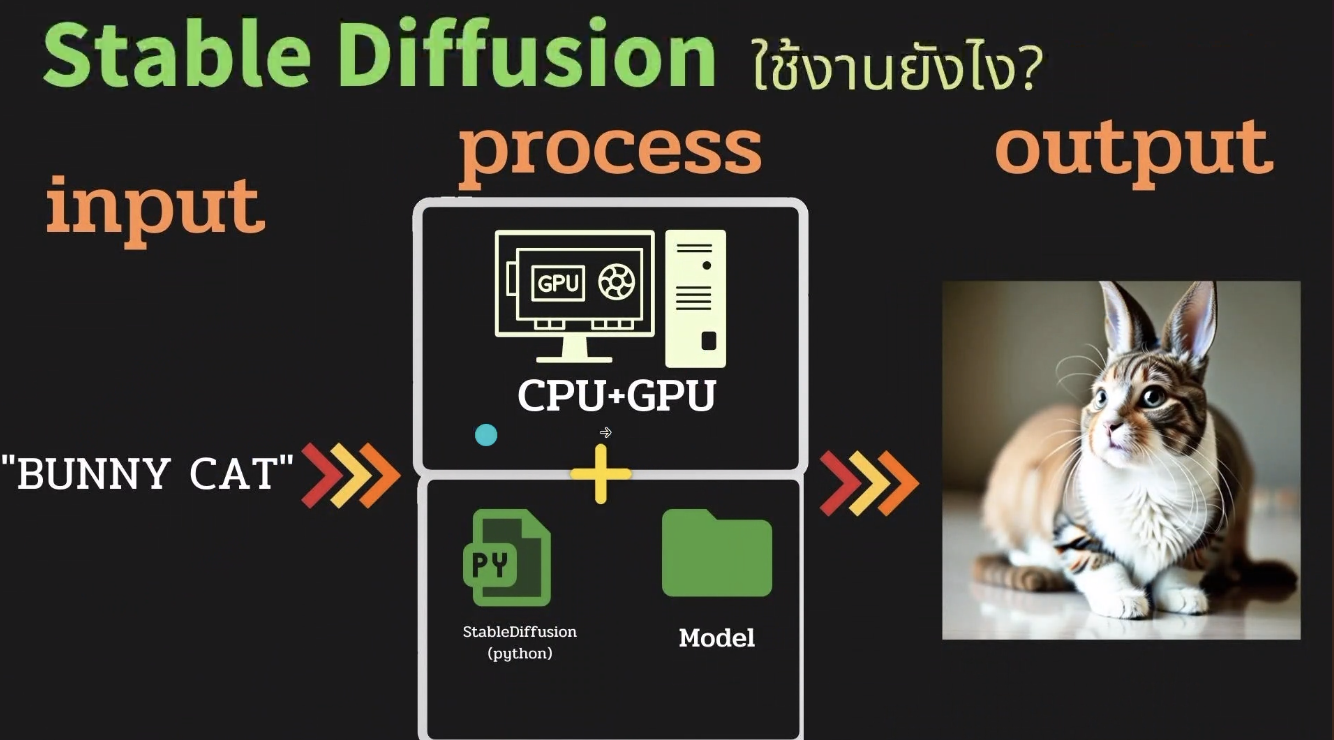
วิธีการทำงาน
มี input เป็น text prompt จากนั้นมี process ข้างใน ประกอบด้วย GPU + python script + file model จากนั้นได้ output เป็นรูปออกมา
วิธีการใช้งาน
การใช้งานมี 3 วิธี
- Web App Tool / Discord
- Local Install
- Cloud CPU + GPU (Google Colab)
Web App Tool / Discord
ข้อดี: ง่าย เลือกตีมได้ ไม่ต้อง install
ข้อเสีย: มีค่าใช้จ่าย, เลือก model ไม่ได้ เพราะเขา fix model ให้เราใช้ตามที่เรากำหนด, มีข้อจำกัดในการใช้งาน
เว็บไซต์ที่น่าสนใจ
 Minseo Chayabanjonglerd
Minseo Chayabanjonglerd
Local Install
เป็นการติดตั้ง python ลงบนเครื่อง เขามีทำให้ดู เหมือนการ run python script ปกติเลย
ข้อดี: ใช้งานได้ฟรี เพราะเป็น open source, custom model ได้
ข้อเสีย: ใช้ hardware เฉพาะ, ใช้ github แก้ error เป็น (แน่นอนสำหรับเดฟอาจจะไม่ใช่ข้อเสียอะไรมาก)

วิธีการติดตั้ง สามารถดูได้ที่คลิปนี้เลย
สิ่งที่ต้องลงแบบคร่าว ๆ
- Python install https://www.python.org/downloads/release/python-3106/
- Git install https://git-scm.com/downloads
- CUDA TOOLKIT https://developer.nvidia.com/cuda-downloads
Cloud CPU + GPU (Google Colab)
ทำเหมือนติดตั้งในเครื่องทุกอย่าง แต่ไปเช่า cloud แทน ในที่นี่คือทำผ่าน Google Colab แต่ไม่ฟรีแล้ว
เราสามารถเปิดตัว colab นี้ แล้วลองดูได้เลย
model ต่าง ๆ สามารถดูได้ที่นี่เลย
 camenduru
camenduruตัว web UI จะหน้าตาประมาณนี้
AUTOMATIC1111ข้อดี: ทำงานบน Cloud CPU+GPU, ติดตั้งง่าย, Custom Model ได้, มีความยืดหยุ่นในการใช้งาน
ข้อเสีย: มีค่าใช้จ่ายในการทำ cloud, มี Vram จำกัด
Parameter
ไม่ว่าลงแบบไหน ก็ใช้เหมือนกัน
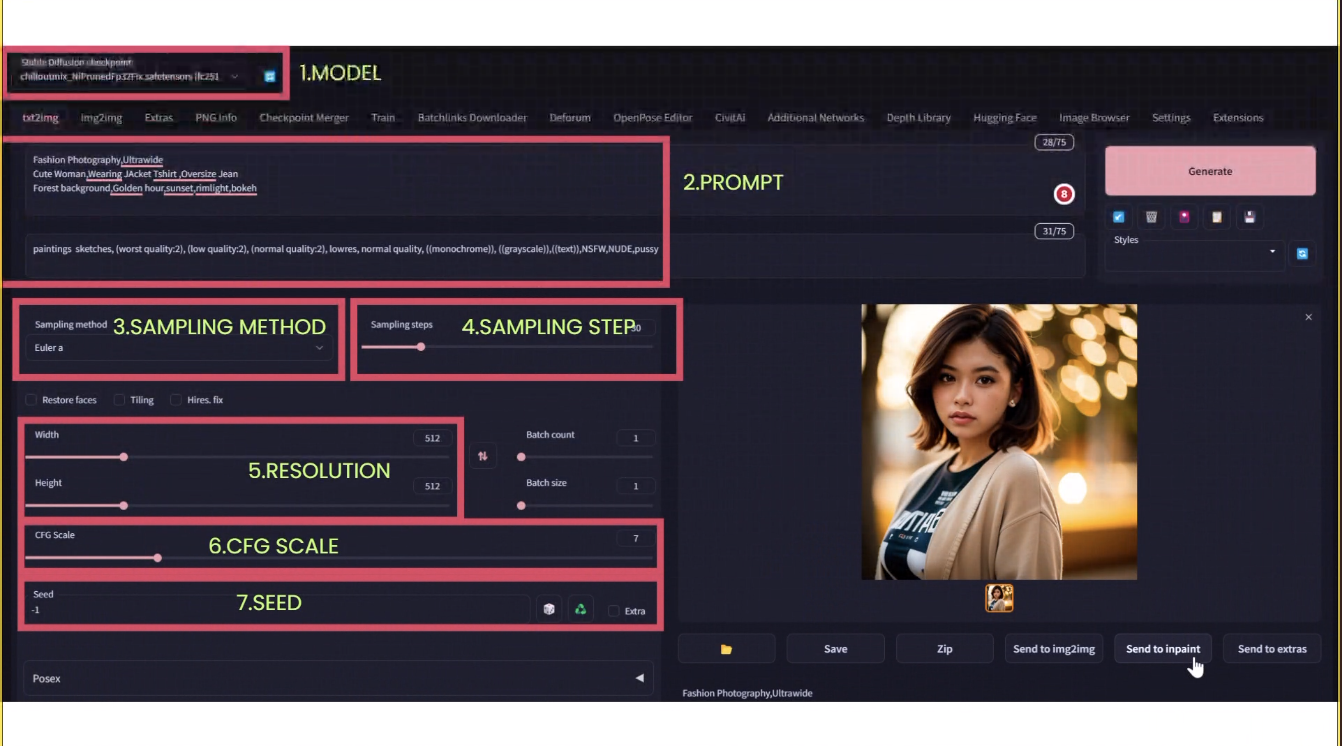

model:
model ใน Stable Diffusion สำคัญที่สุด (ส่วน Midjourney ให้ความสำคัญกับ prompt)
ด้วยความที่ Stable Diffusion เป็น open source เลยเอา model มาเทรนกันต่อได้
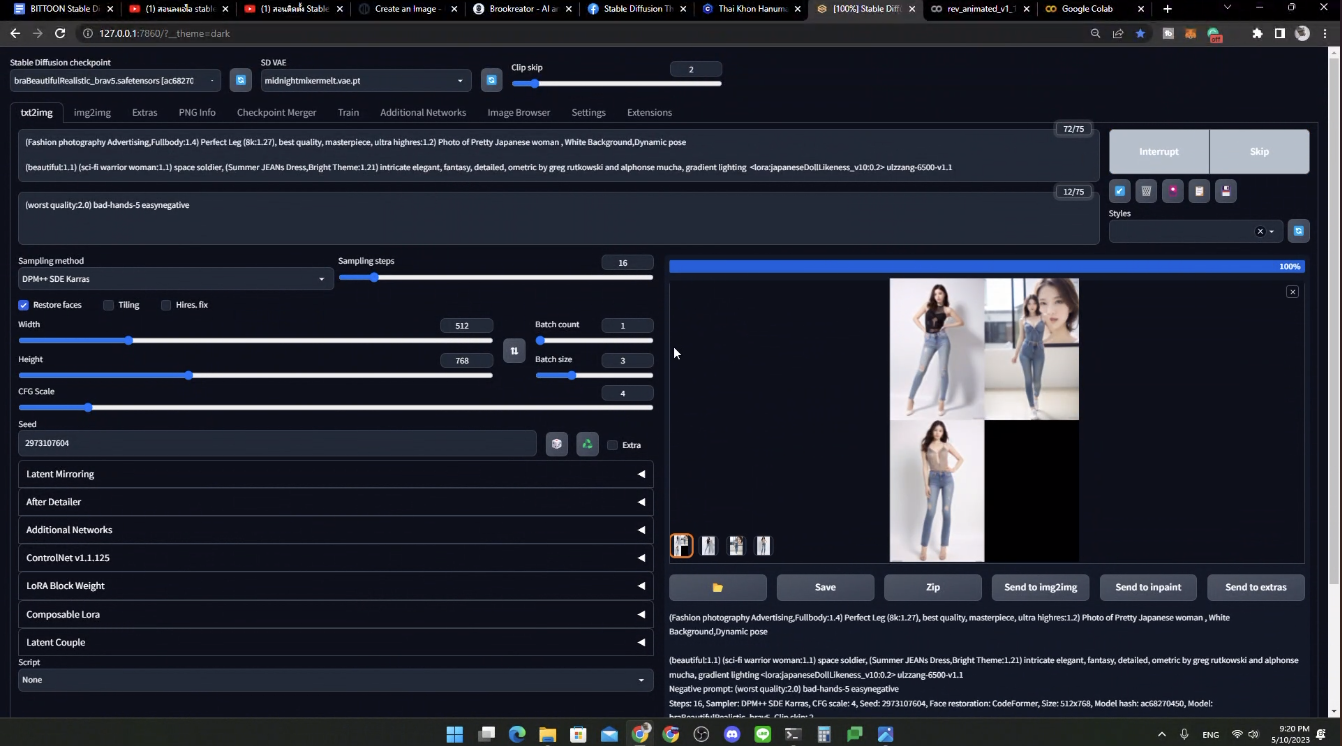
ถ้าเราใช้ prompt เดียวกัน แต่เปลี่ยน model ก็จะได้หน้าตารูปที่แตกต่างกันนะ
และเราสามารถเอา model มาผสมกัน เพื่อให้ได้ model ใหม่ อย่างรูปที่ 4 ที่ใช้อย่างละ 0.5

prompt:
เป็น input text ว่าเราต้องการภาพแบบไหน และสามารถใส่สิ่งที่เราไม่ต้องการได้ด้วยนะ ใน negative prompt
สิ่งที่ควรใส่ใน positive prompt
- มุมกล้อง: art medium, art style, มุมกล้อง, ประเภทของ artwork
- subject: รายละเอียดของวัตถุ ชุด หน้าตา จำนวน object
- background: รายละเอียดของพื้นหลัง สภาพแสง รายละเอียดเพิ่มเติม
- keyword: modify keyword เพื่อสร้าง style หรือเพิ่มรายละเอียด หรือ composition ที่ดีขึ้น
ในนี้สามารถเคาะบรรทัดได้นะ

ในส่วนของ negative prompt (ใน Midjourney เราจะเห็นตรงนี้ไม่ชัดนะ) ใช้ในการตัดสิ่งที่เราไม่ต้องการ
สิ่งที่ควรใส่ สามารถลอกไปได้เลยจ้า สำหรับตัด latent space เพื่อเพิ่มคุณภาพ
(WORST QUALITY:2), (LOW QUALITY:2), (NORMAL QUALITY:2), LOWRES, NORMAL QUALITY, ((MONOCHROME)), ((GRAYSCALE)), ((TEXT)),NSFW, NUDEสิ่งที่เราควรใส่ ถ้าเราไม่เอา 18+ กันภาพนู้ดหลุด มี NSFW (Not safe for work = ไม่ปลอดภัยสำหรับเปิดในที่ทำงาน) และ NUDE

อยากรู้เกี่ยวกับ prompt หรืออยากทดลองสร้าง prompt สามารถไปดูได้จากเว็บเหล่านี้เลย
- https://promptomania.com/stable-diffusion-prompt-builder/
- https://openart.ai/discovery
- https://lexica.art/
- https://prompthero.com/stable-diffusion-prompts
sampling method:
เป็นชนิดของ algorithm ในการ sampling ภาพ
algorithm ที่ใช้ในการ de-noise ก็จะมี Euler, DDIM, PM++

ถ้าเราใช้ prompt เหมือน seed เหมือน แต่ sampling ต่าง จะได้ผลที่แตกต่างกันไปด้วย แล้วก็ 3 ตัวหน้าเป็น play-self เนอะ

sampling step:
ใช้ในการ de-noise ภาพ มีค่าแนะนำ 20 -30 เพราะค่ายิ่งเยอะ ยิ่งใช้เวลานานเนอะ
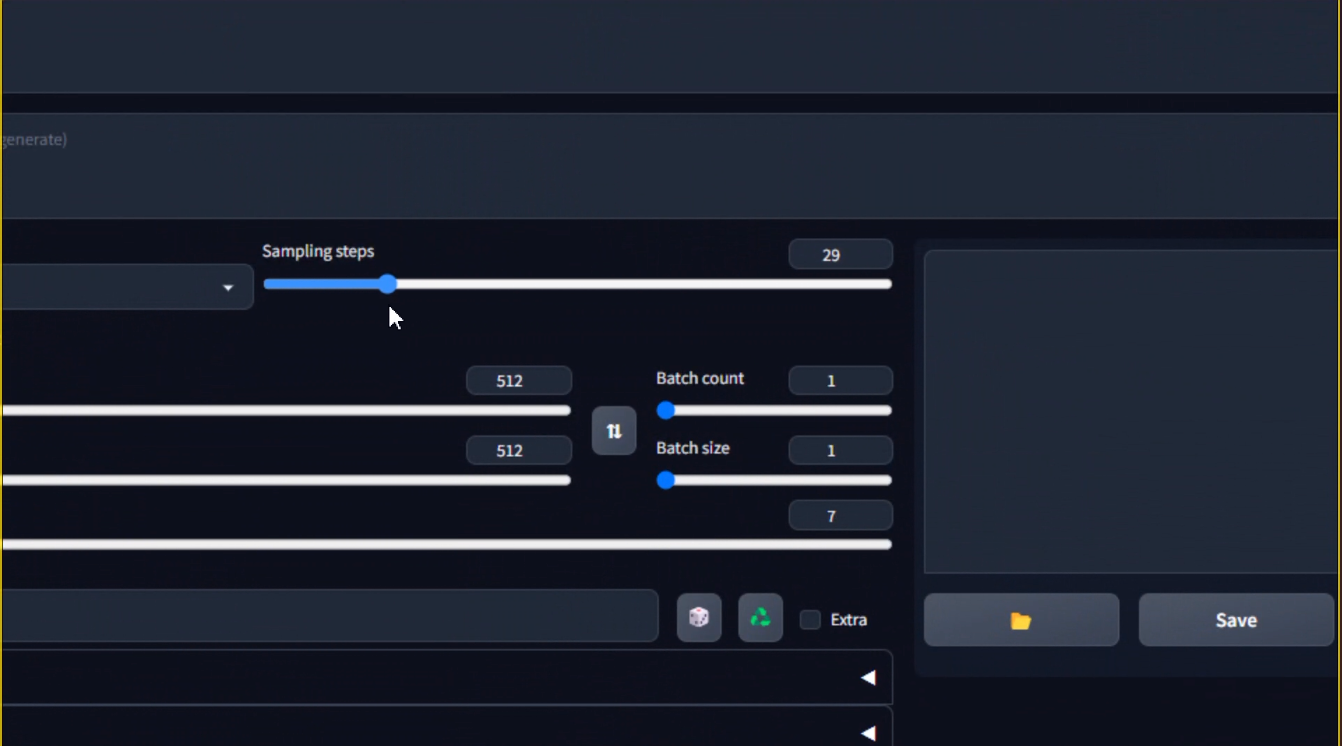

resolution:
เป็นการกำหนดขนาดภาพ ว่าเราต้องการให้ภาพมีความกว้าง และความยาวเท่าไหร่ ในหน่วย pixel


CFG scale:
classifier-free guidance scale เป็น parameter สำหรับเอามาตั้งให้ภาพที่เราจะเจน มีความใกล้เคียงกับ prompt มากที่สุด มีค่าแนะนำ คือ 7 - 11 ถ้าเกินกว่านั้นภาพจะแปลกไปเลย


seed:
seed เป็นตัวเลขในการกำหนดค่า random ของ noise ในการสร้างภาพ
ถ้าเราต้องการให้ random seed ทุกครั้งที่สร้างภาพ ให้ใส่ค่า -1 นะ

และถ้าเราตั้งค่า seed เหมือนเดิม เราก็จะได้ภาพเหมือนเดิมนะ

Advance
มากล่าวถึงส่วนที่เป็น advance กันบ้าง
- Restore Face แก้ไขภาพใบหน้า
- Upscaler เป็น method ที่ใช้ในการ upscale
- Hires.fix เป็นการขยายภาพ และปรับรายละเอียดภาพ โดยการอัพ scale ภาพ ให้มีความชัดมากขึ้น
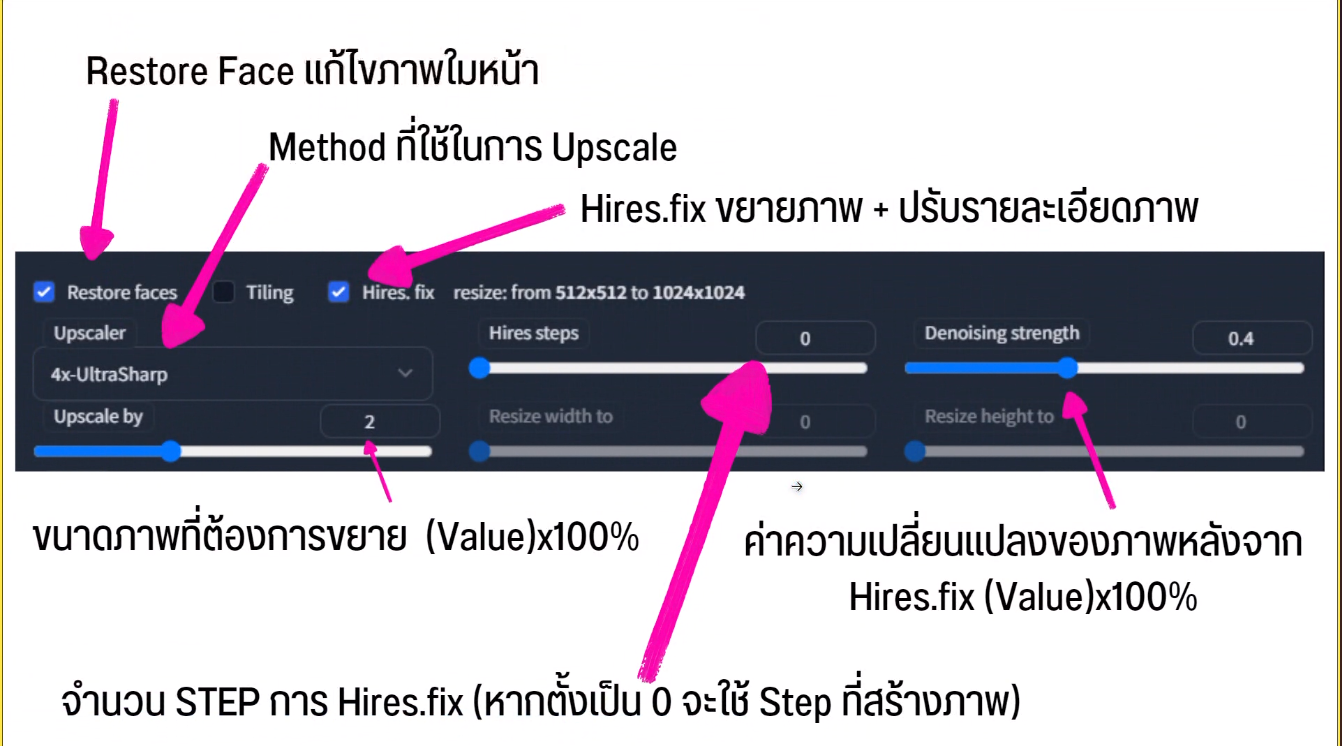

ภาพชัดขึ้น เกิดมาจากการสร้างภาพใหม่ อิงภาพเดิม ถ้าใช้ค่าตํ่า จะเป็นการอิงภาพเดิม

Cheatsheet
setting พื้นฐาน / denoise str ใส่ให้อิงกับรูปเดิม
Sampling: Euler a
Steps: 25
CFG: 7
Seed: -1
Hires.Fix On
Hires Step: 0*
Denoise str : 0.4
Negative Prompt: NSFW,NUDE,(worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)),((text)),logo

อันนี้ผลที่ได้เมื่อปรับค่า denoise strength

สามารถเจนหลายรูป แล้วเลือกรูปที่เราชอบได้ และสามารถกด reuse หรือ recycler ได้เลย ถ้าอยากเจนรูปใหม่จากของเดิม โดยจะอิงจากภาพที่ show
Model มีอะไรบ้างนะ?
model สำหรับ Stable Diffusion เป็นตัวหลักในการสร้างภาพ
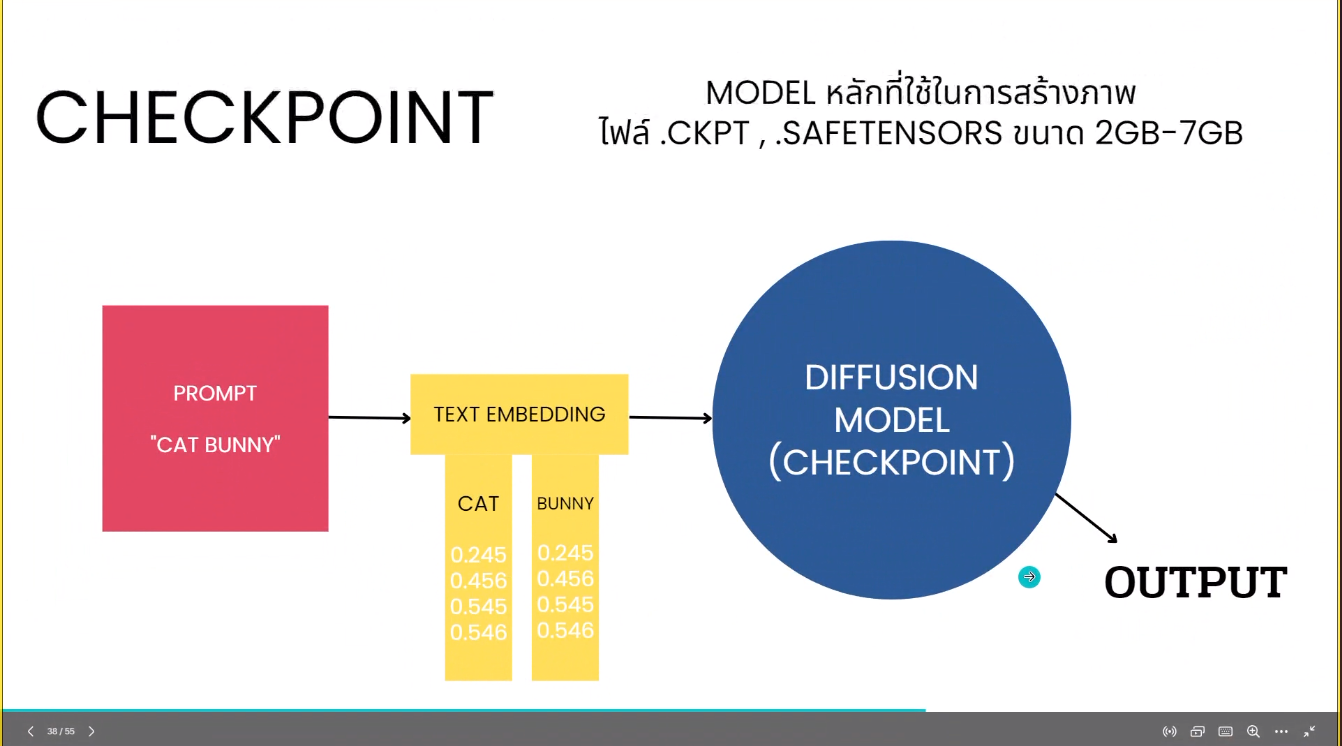
Checkpoint
เป็น model หลักที่ใช้ในการสร้างภาพ จะเป็นไฟล์ .ckpt หรือ .safetensors มีขนาดใหญ่ โดยทั่วไปจะมีขนาด 2 - 7 GB เลยล่ะ
ตัวอย่าง



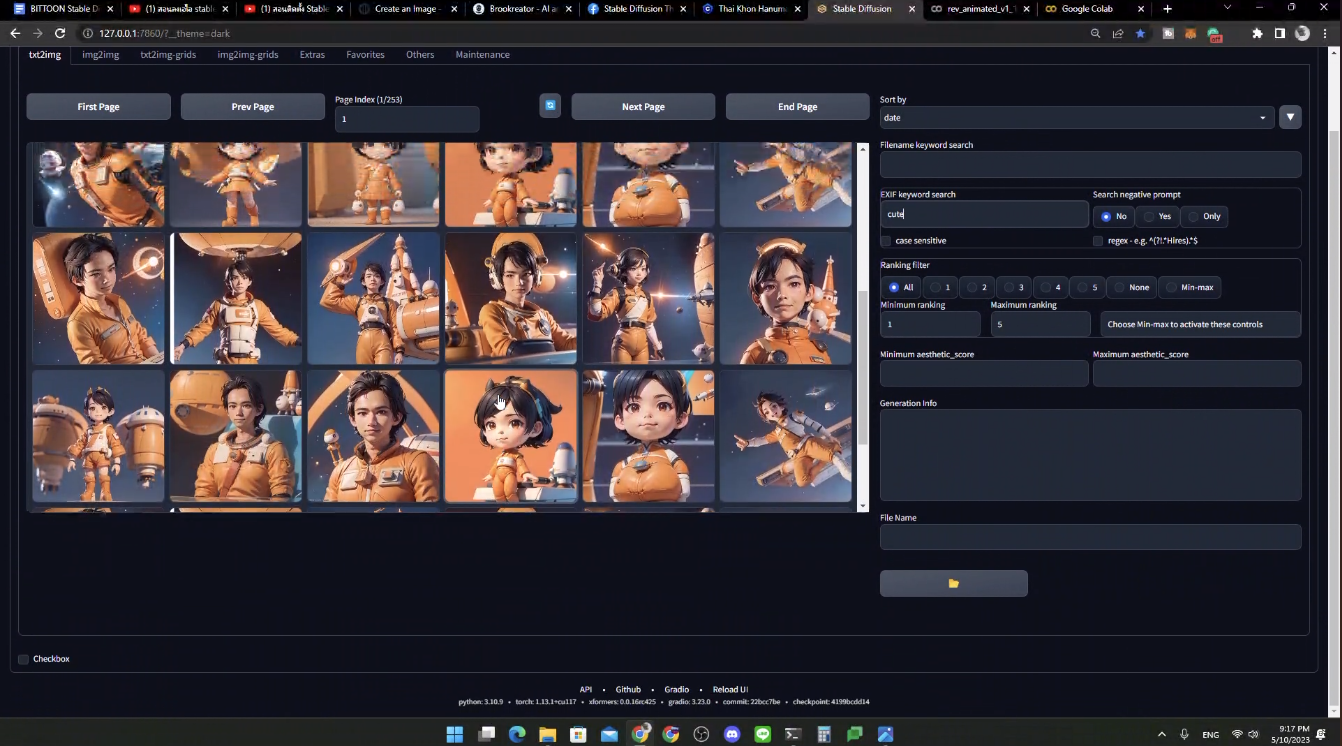
เราสามารถหา model ต่าง ๆ ได้จาก Civitai นี้เลย
วิธีการเลือกคือ ให้ไป filter checkpoint
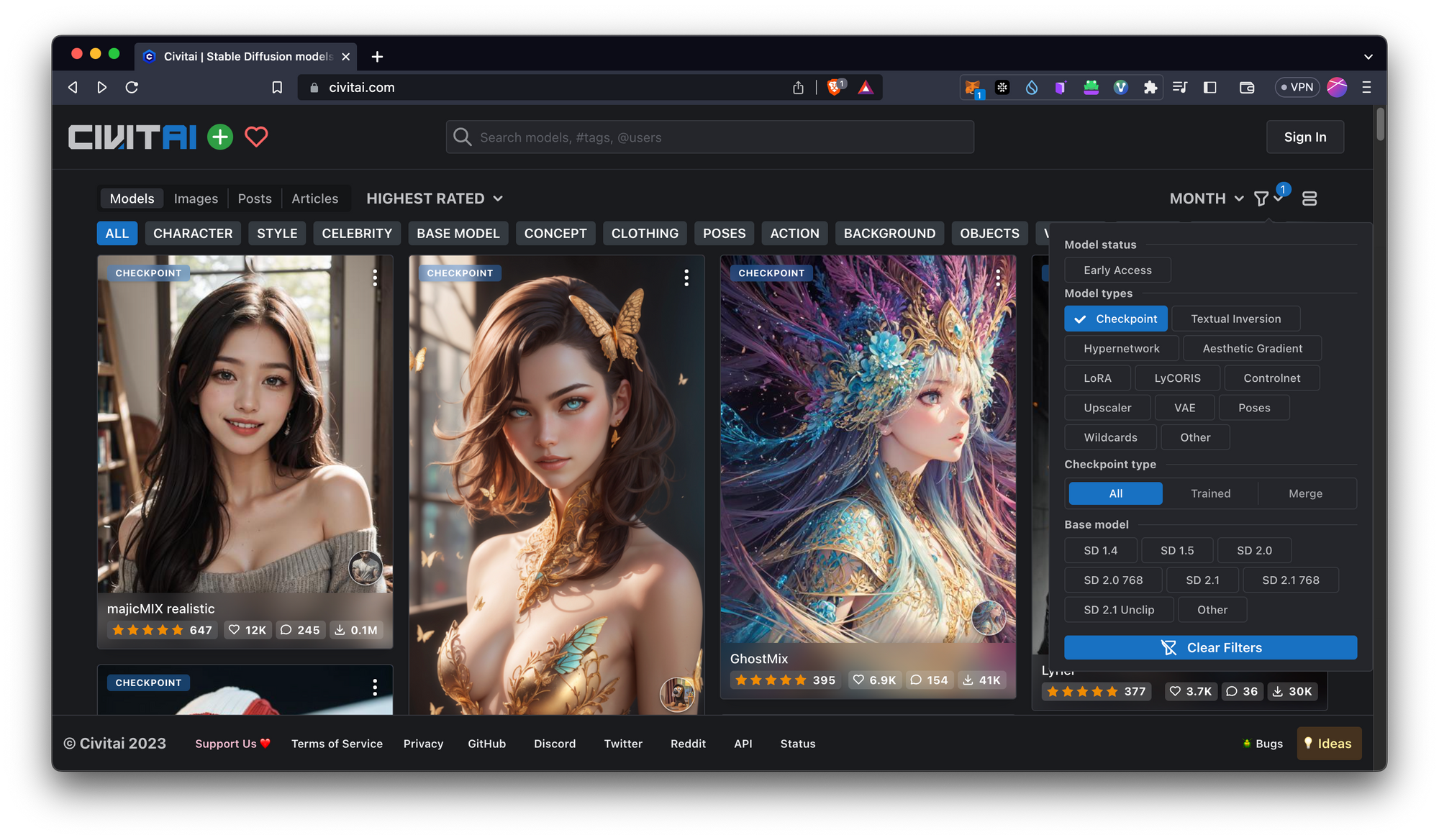
เลือก model ที่เราต้องการโหลด แล้วกด Download ได้เลย
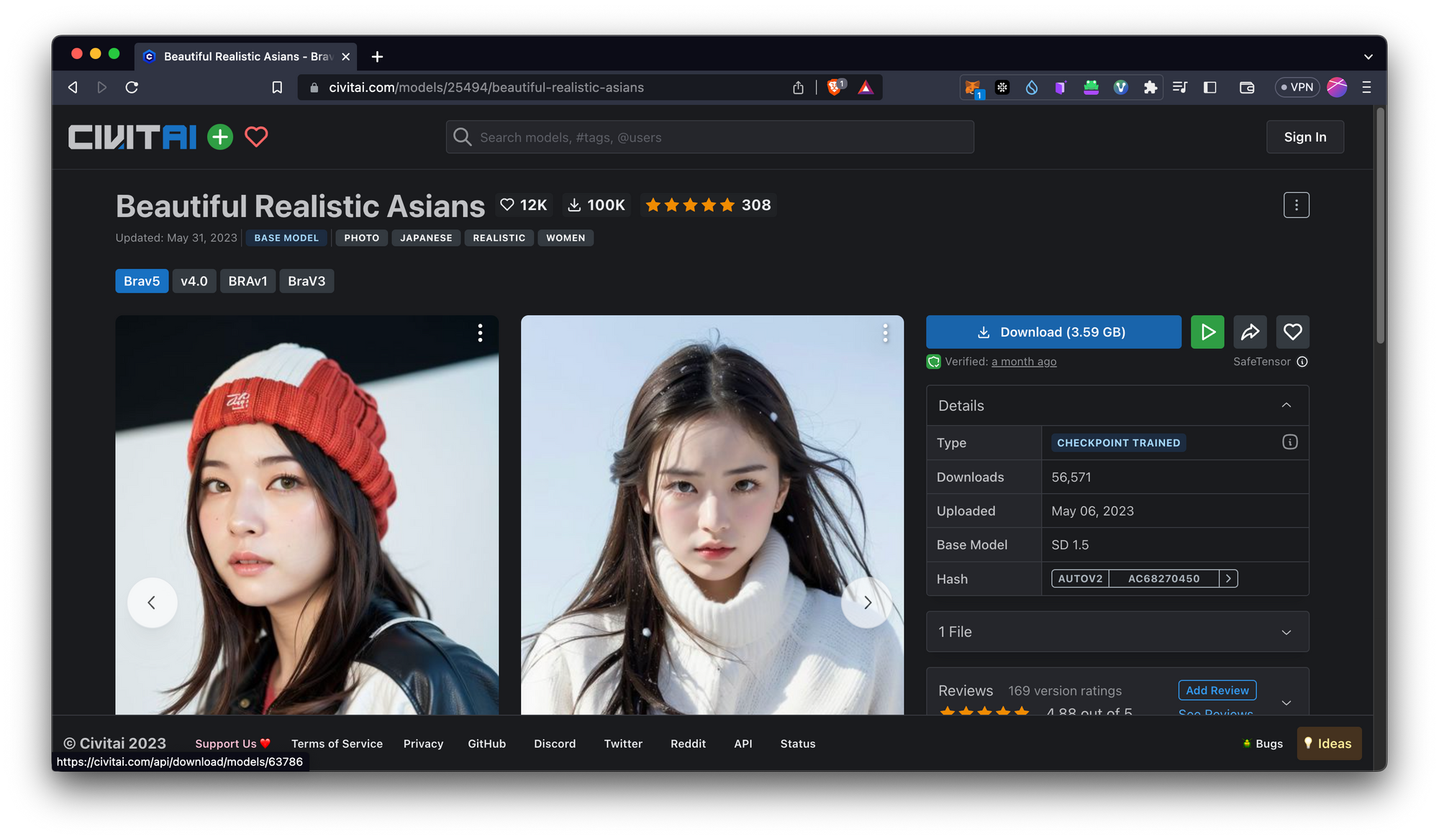
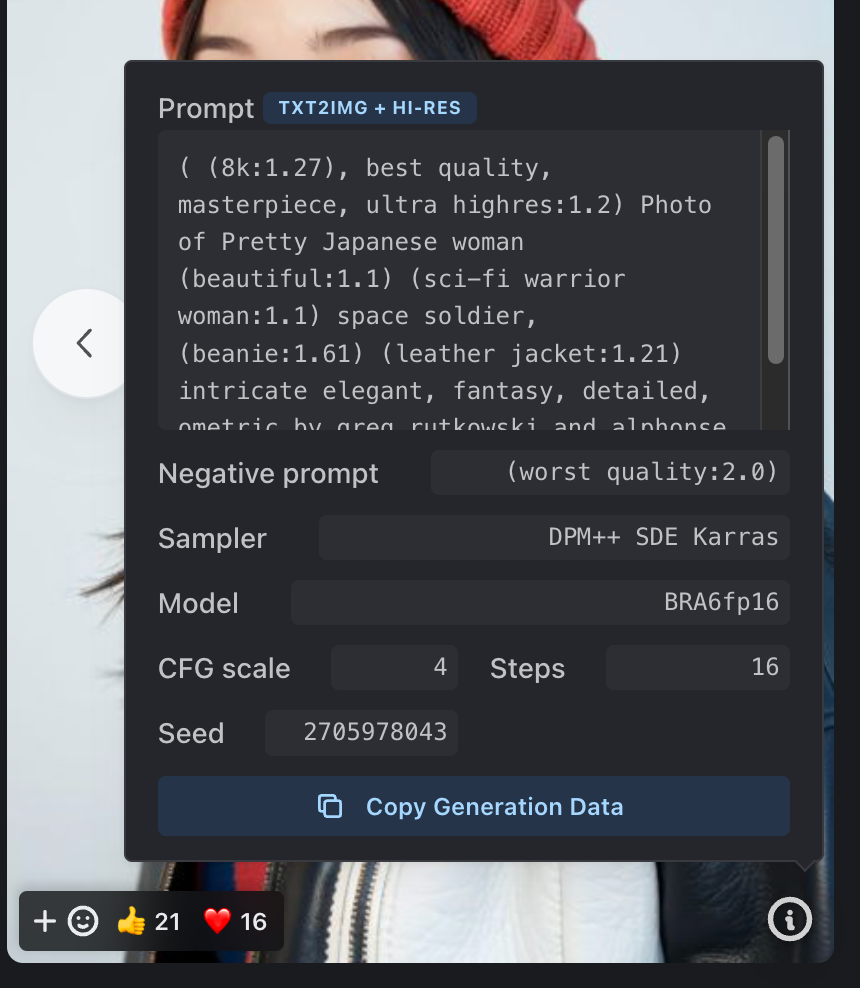
เราสามารถกดไปดู info ของรูปได้ และกด copy generate data เพื่อนำไปใช้ต่อได้เลยจ้า ในส่วนของ prompt เนอะ
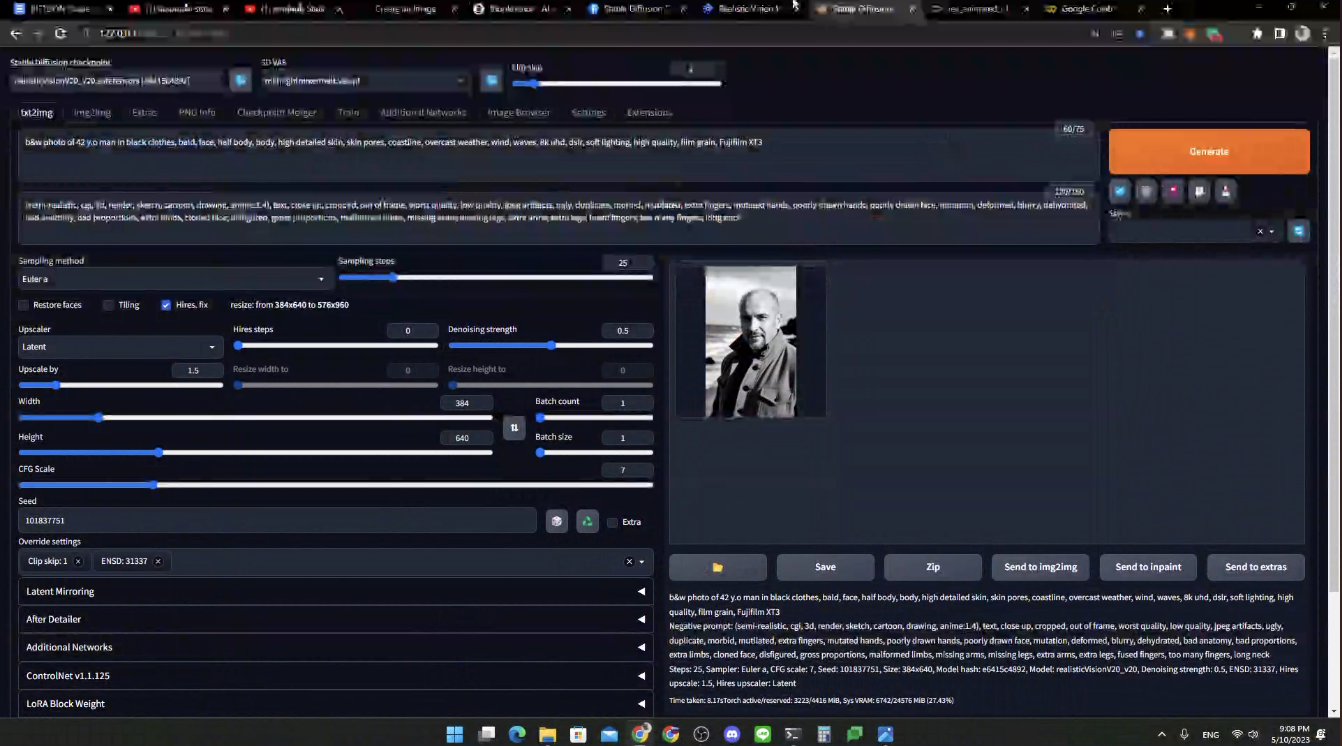
LORA Model
เป็น model เสริมที่ใช้ในการสร้างภาพ มีขนาด 9 - 250 MB ซึ่งขนาดจะเล็กกว่า model ปกติ เป็นไฟล์นามสกุล .ckpt และ .safetensors
ตัว lora เป็นสไตล์ภาพ ข้างในจะมีแต่ละ model ที่มี lora ครอบอยู่ สามารถเอาไปจับอะไรก็ได้ เพราะเป็นอันเล็ก ๆ ข้อดี ค่อนข้างยืดหยุ่น เช่น เอาหน้าตัวเองเทรนเข้าไป เทรนให้คนใส่ชุดที่เราต้องการก็ได้เช่นกัน




สไตล์ภาพ object filter
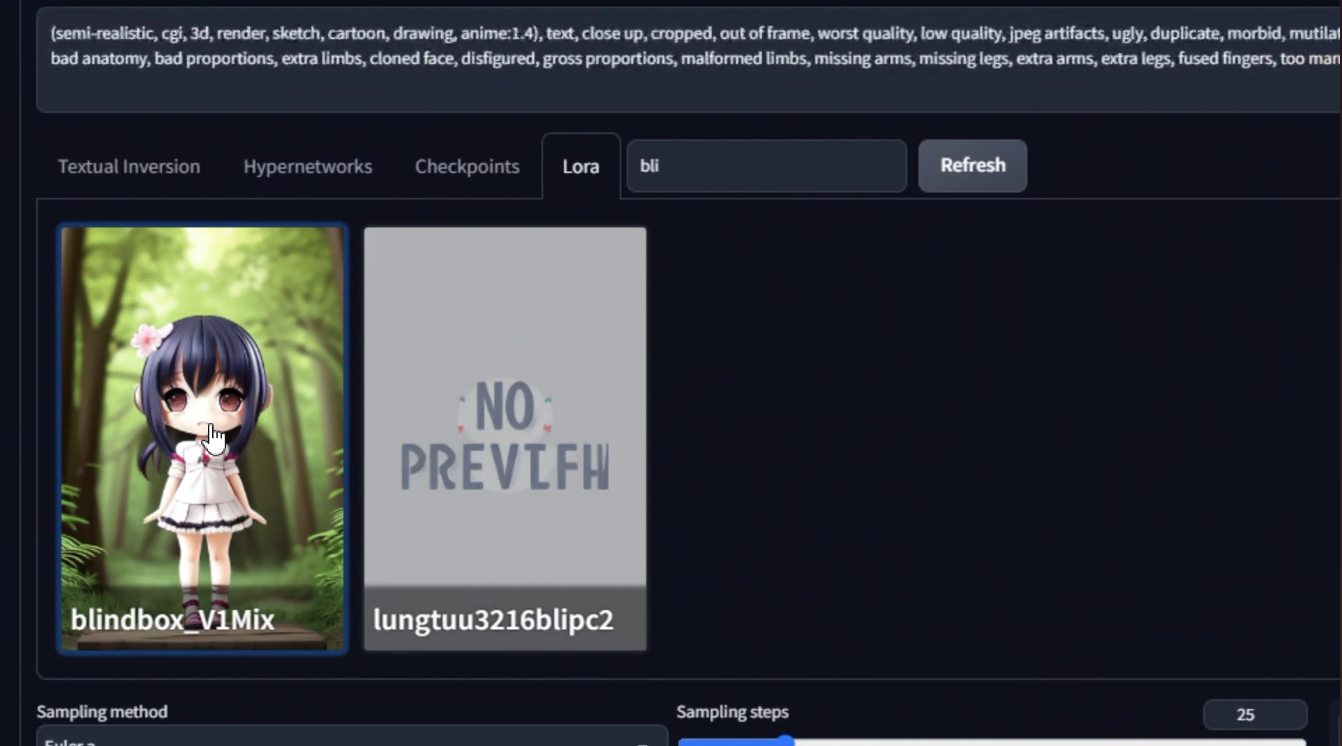
และเราสามารถนำ lora มาผสมกันได้ด้วยนะ
Textual Inversion
เป็นส่วนเสริมในการทำภาพต่าง ๆ ในที่นี้กล่าวถึง Controlnet เอามา control post ต่าง ๆ ได้ สามารถทำ dynamic pose ซึ่ง default มันเป็น random และใส่ pose ที่เราต้องการได้ด้วยน้า
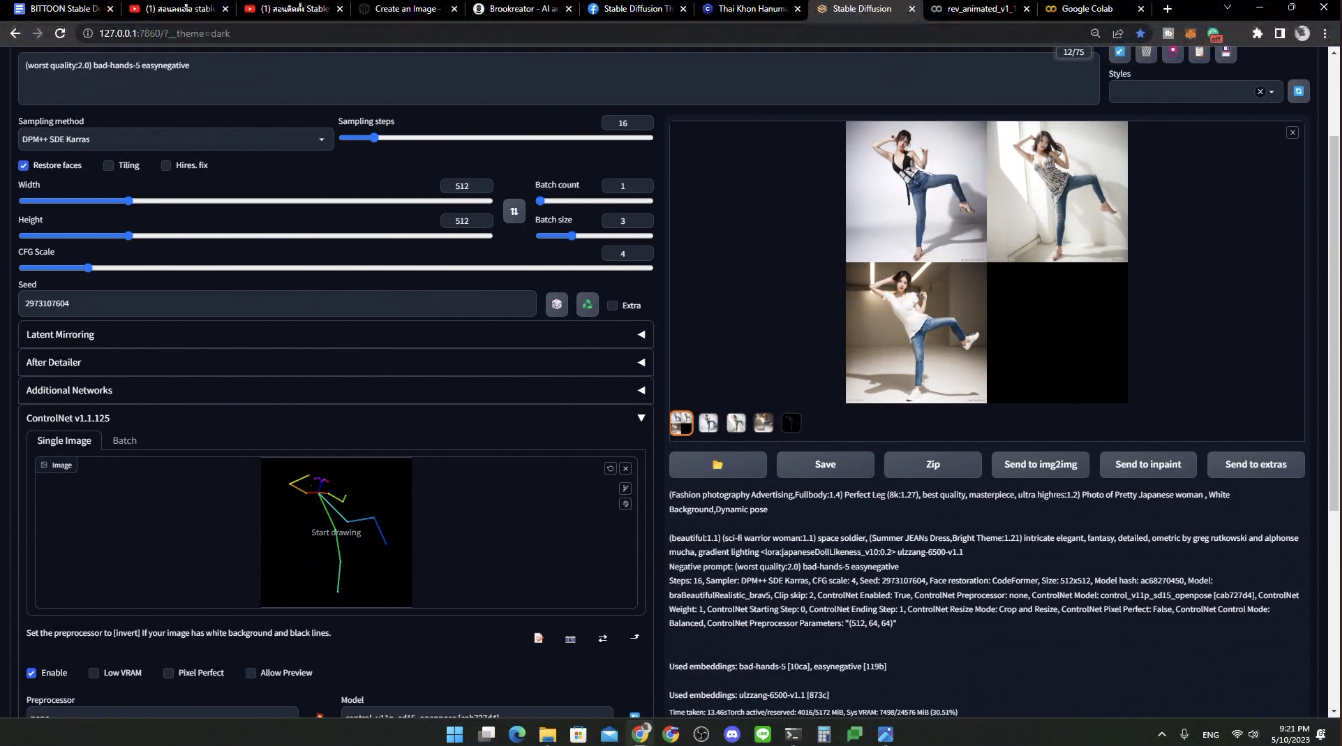
- openpose: ใน version ปัจจุบัน control สีหน้า และนิ้วได้ด้วย
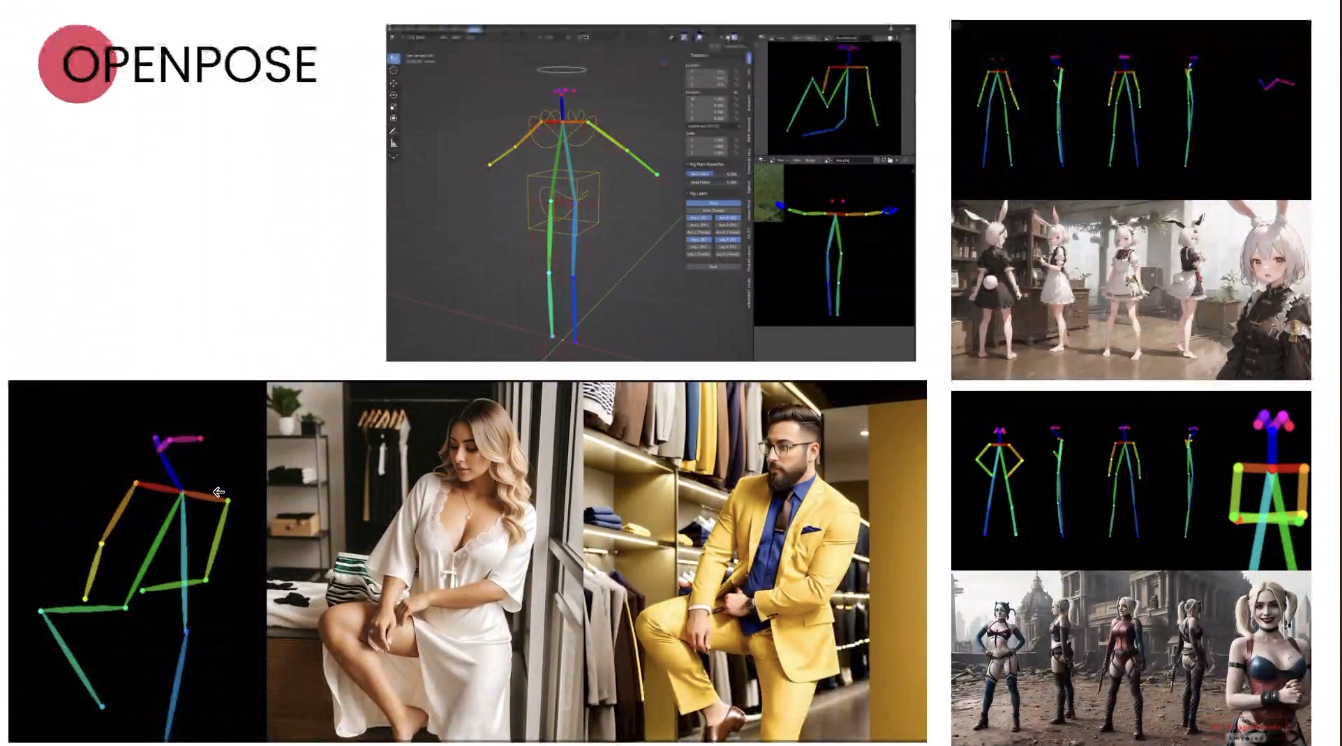
เราสามารถวาดแบบนี้ หรือเอาภาพที่มี มา pre-process ได้
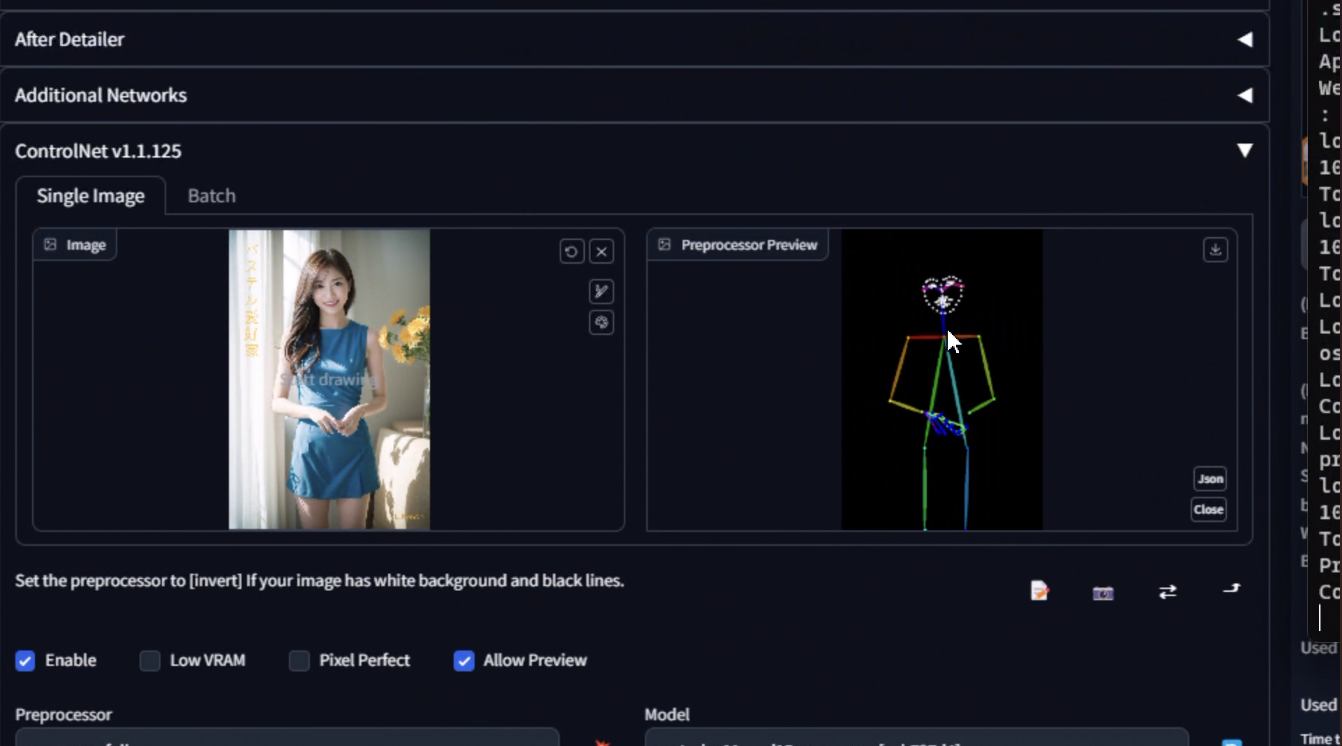
ตัว OpenPoses สามารถดูเพิ่มเติมได้ที่นี่จ้า
อันนี้เว็บที่กำหนดท่าทางอีกเว็บนึง ลองไปเล่นในนี้ได้เลยจ้า

- depth: เอาภาพมาแปลง ใส่ prompt ลงไป สำหรับภาพที่มีความลึก

- scribble: ภาพสเก็ต แล้วให้ AI ตีความเป็นภาพตาม prompt

สามารถดู ControlNet เพิ่มเติมได้ที่นี่เลย
lllyasvielอื่น ๆ
- ต้นทุนการเทรน 50 ล้านเหรียญ → open source ทำให้คอมมูเติบโตได้เร็ว
- img2img เอาภาพเดิม มาสร้างเป็นภาพใหม่ อิงแค่รูปทรง สี

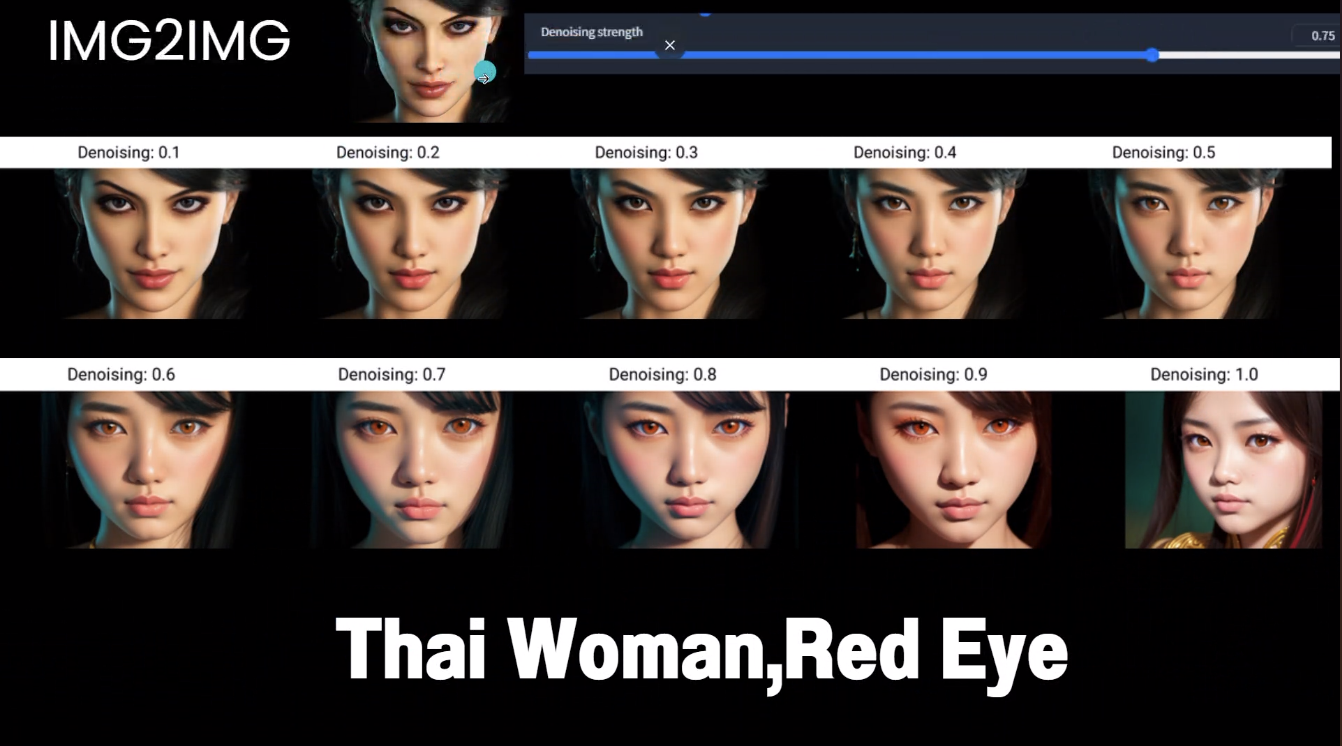
และสามารถสร้าง prompt จากภาพได้ด้วยนะ

- ภาพ AI เจนมาไม่มีลิขสิทธิ์ เราทำภาพมีลิขสิทธิ์โดยการปรับแต่งเพิ่ม
- มีหนังสั้นที่ทำด้วย AI ด้วยนะ เป็นของ Netfilx ชื่อว่า Dog and Boy นะ

DEMO & Case Study
อันนี้ตัว colab ที่ใช้เนอะ
camenduruเมื่อรัน collab เสร็จแล้ว กดดูหน้าเว็บอันที่เป็น url gradio.live นะ
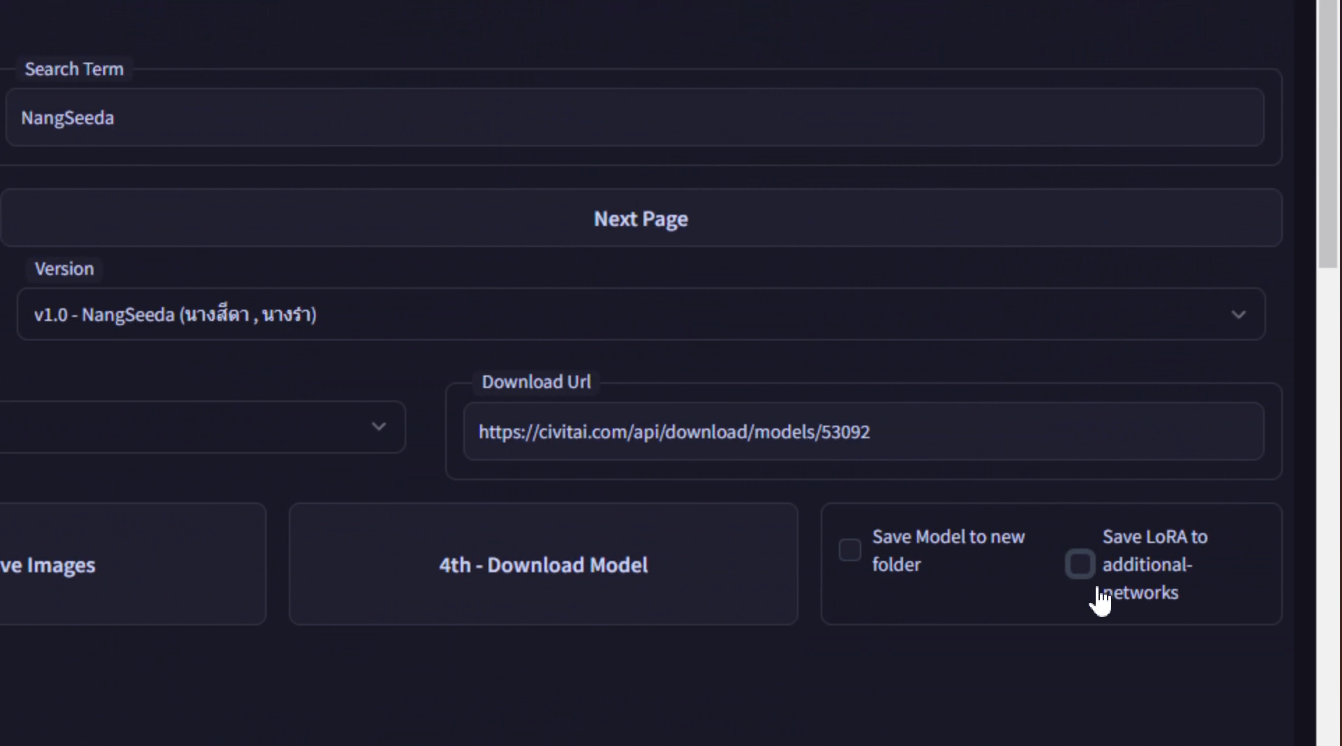
ในการใช้ LoRA ต้องเอาอันนี้ Save LoRA to additional-networks ออกทุกครั้ง / show extra network / copy trigger word ไปใน prompt ได้
ดูภาพที่เคยเจนได้ด้วยนะ
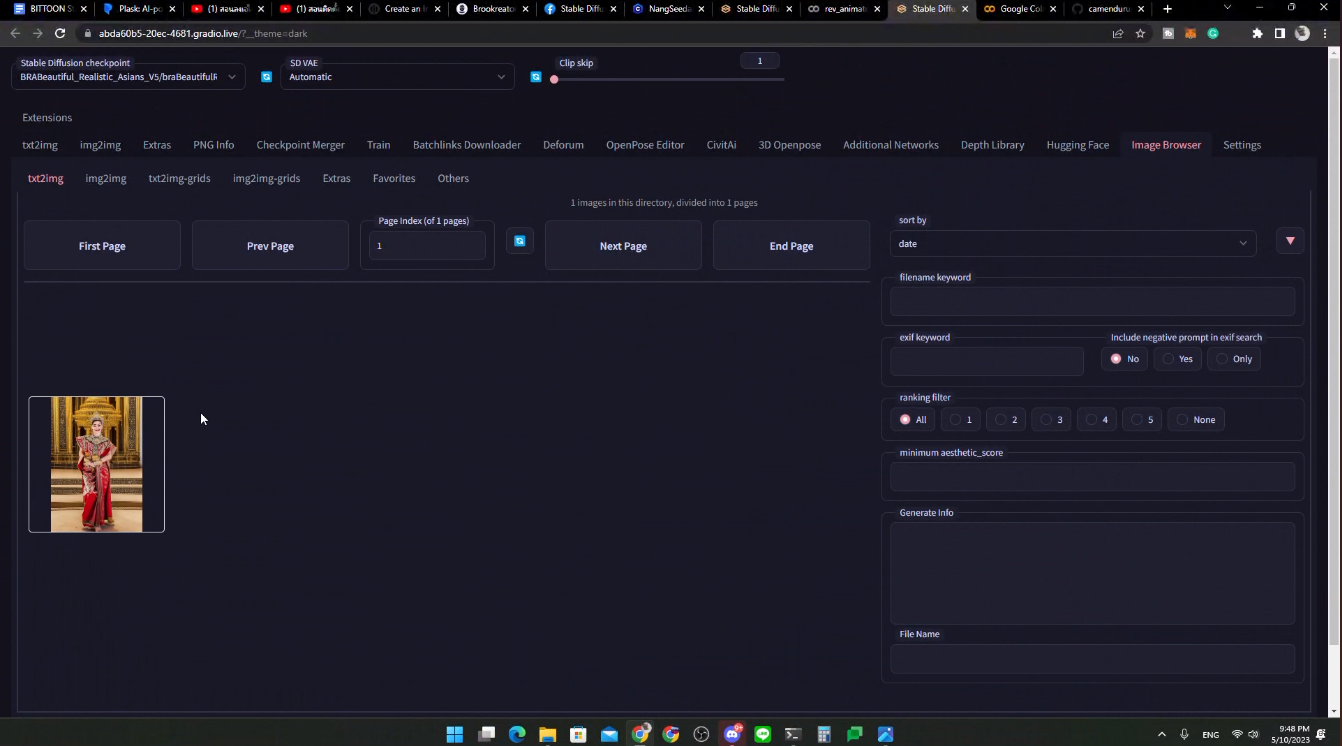
ทุกครั้งที่เราปิด Colab เราจะต้องรันใหม่เสมอ ดังนั้น model ที่เราโหลดไป เราจะต้องลงใหม่ โดยวิธีการต่าง ๆ จะตามนี้เลย
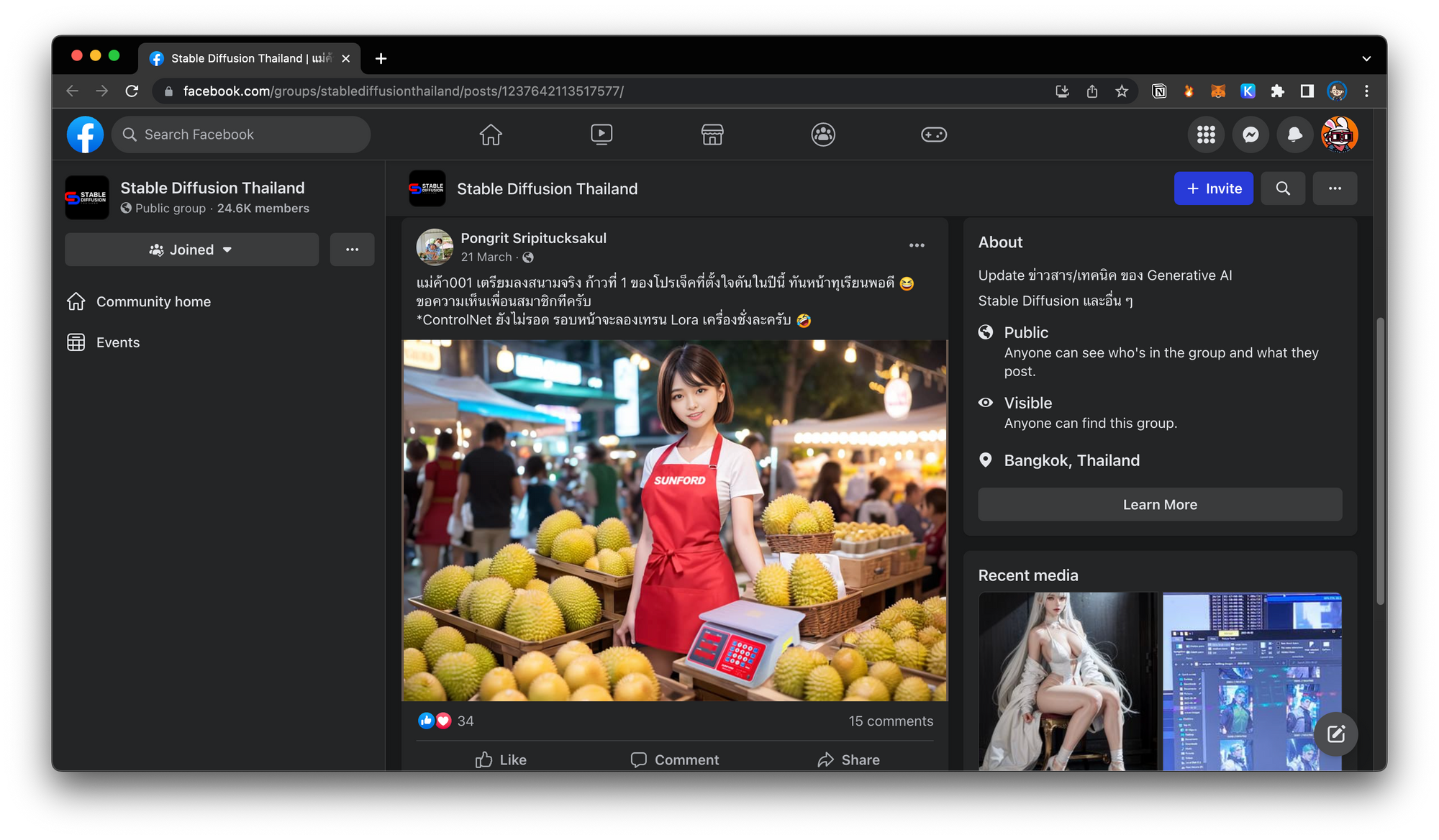
อันนี้เป็น case study คนนี้ generate ภาพมาช่วยขายของ โดยรูปนี้ใส่ logo ของเขา พร้อมแนบตาชั่งไว้ด้วย ทำจนได้น้องคนนี้มาช่วยขายของจริงจัง
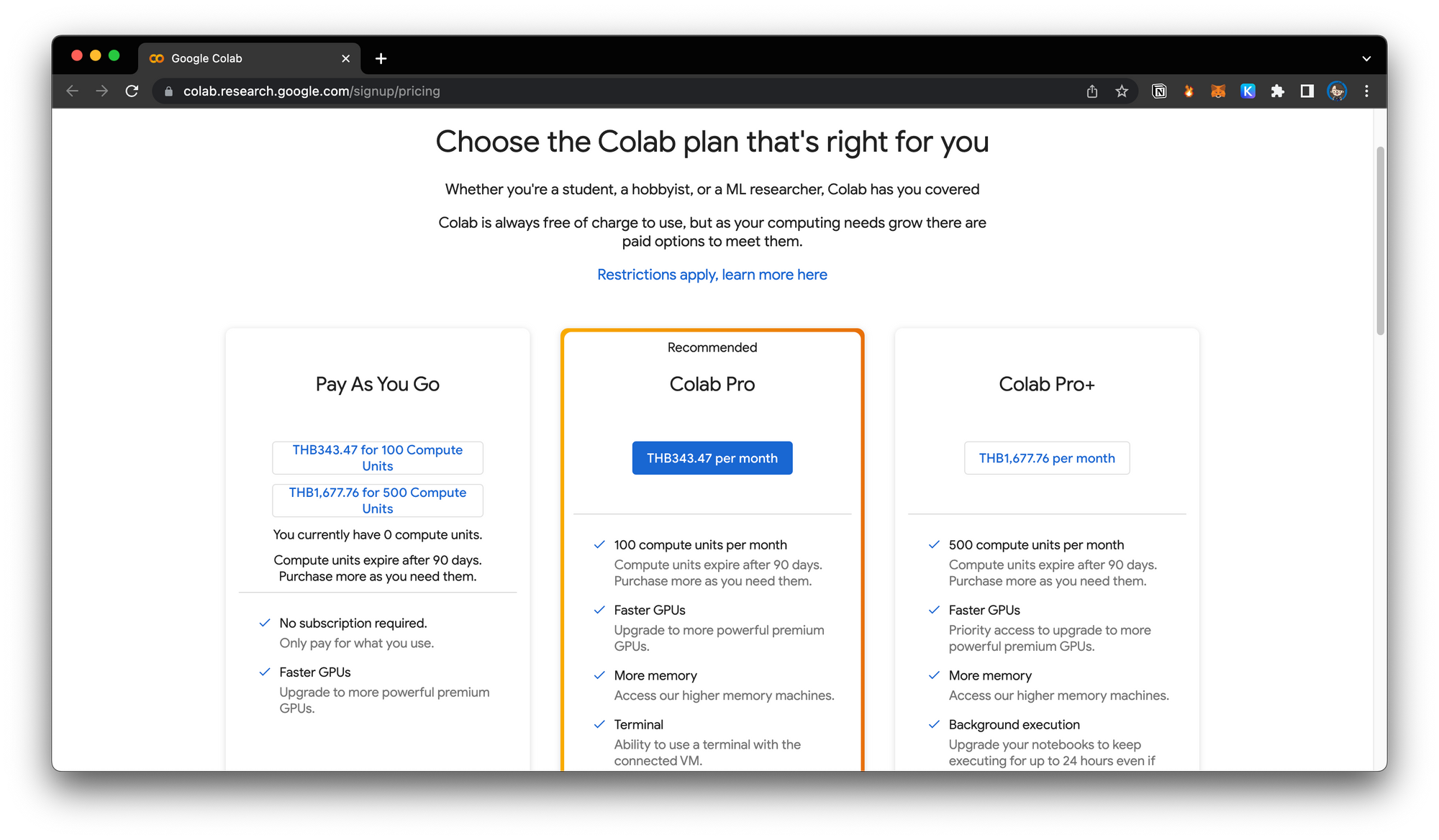
และเนื่องด้วย Google Colab ใช้ฟรีไม่ได้ ต้องเสียเงิน เดือนละประมาณ 10 USD
ทั้งหมดก็จะเป็นประมาณนี้นะ หวังว่าอ่านแล้วไม่งงน้า
ติดตามข่าวสารตามช่องทางต่าง ๆ และทุกช่องทางโดเนทกันไว้ที่นี่เลย
ติดตามข่าวสารแบบไว ๆ มาที่ Twitter เลย บางอย่างไม่มีในบล็อก และหน้าเพจนะ
สวัสดีจ้า ฝากเนื้อฝากตัวกับชาวทวิตเตอร์ด้วยน้าา
— Minseo | Stocker DAO (@mikkipastel) August 24, 2020